Adaline - Adaptive Linear Neuron
Just continuing with my explanation about Artificial Neural Networks in a simple way.
The Adaline (Adaptive Linear Neuron or later Adaptive Linear Element) network, proposed by Widrow and Hoff in 1960, has the same structure as the Perceptron, differentiating only in the algorithm of training.
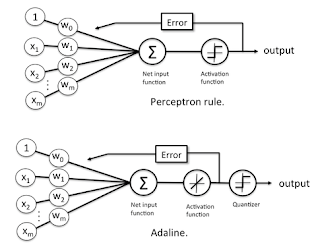
She is an adaptive network, with the Inclusion of a pioneering algorithm for the training of multi-layered networks, the training algorithm of the Delta rule, the Delta rule algorithm is based on the method of least squares, she has a smoother learning method.
Their goal is Perform local iterations to get the function and thus set the values of the weights when the minimum was found.
Through an arbitrary point (vector of weights started randomly), the algorithm runs, at each iteration, the surface of the error function towards the point of Minimum.
The Adaline (Adaptive Linear Neuron or later Adaptive Linear Element) network, proposed by Widrow and Hoff in 1960, has the same structure as the Perceptron, differentiating only in the algorithm of training.

She is an adaptive network, with the Inclusion of a pioneering algorithm for the training of multi-layered networks, the training algorithm of the Delta rule, the Delta rule algorithm is based on the method of least squares, she has a smoother learning method.
Their goal is Perform local iterations to get the function and thus set the values of the weights when the minimum was found.
Through an arbitrary point (vector of weights started randomly), the algorithm runs, at each iteration, the surface of the error function towards the point of Minimum.
Adaline is a single layer neural network with multiple nodes where each node accepts multiple inputs and generates one output. Given the following variables:as
- is the input vector
- is the weight vector
- is the number of inputs
- some constant
- is the output of the model





then we find that the output is . If we further assume that



then the output further reduces to:

Learning algorithm
Let us assume:
- is the learning rate (some positive constant)
- is the output of the model
- is the target (desired) output


then the weights are updated as follows . The ADALINE converges to the least squares error which is .[6] This update rule is in fact the stochastic gradient descent update for linear regression.[7]


Here an example of the both algorithms:



Comentários
Postar um comentário